使用python批量将html文件转为word文档
因为项目需要,前段时间编写了一个使用python批量将html文件转为word文档的程序,今天分享给大家
源码:
import os
import pypandoc
# pypandoc.convert_file(r'C:/Users/Administrator/Desktop/ss/2022年福建中考数学真题及答案_docx/index.html','docx',outputfile='test.docx')
path = r"C:\Users\Administrator\Desktop\s"
filelist = os.listdir(path)
zong = len(filelist)
i = 0
j=0
for dirs in filelist:
try:
if dirs.endswith("_docx"):
htmlname = dirs.replace("_docx", "")
with open(path + '\\' + dirs + '\\index.html', 'r+', encoding='utf-8') as htmlfile:
htmlstr = htmlfile.read()
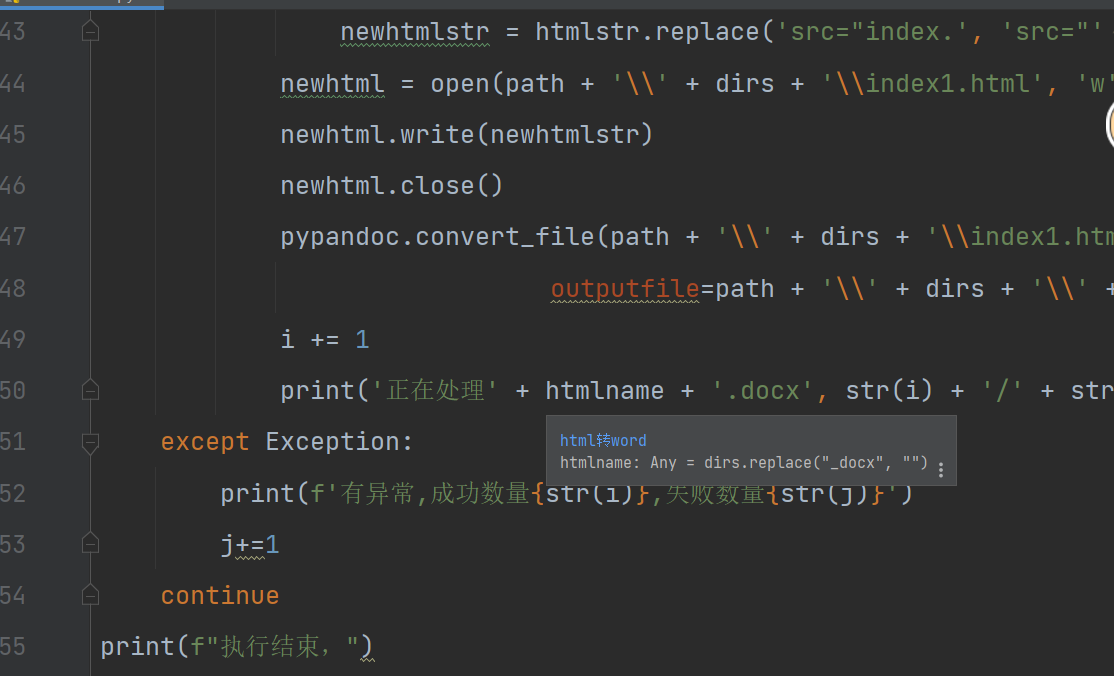
newhtmlstr = htmlstr.replace('src="index.', 'src="' + path + '\\' + dirs + '\\' + 'index.')
newhtml = open(path + '\\' + dirs + '\\index1.html', 'w', encoding='utf-8')
newhtml.write(newhtmlstr)
newhtml.close()
pypandoc.convert_file(path + '\\' + dirs + '\\index1.html', 'docx',
outputfile=path + '\\' + dirs + '\\' + htmlname + '.docx')
i += 1
print('正在处理' + htmlname + '.docx', str(i) + '/' + str(zong), f"成功数量{str(i)},失败数量{str(j)}")
elif dirs.endswith("_doc"):
htmlname = dirs.replace("_doc", "")
with open(path + '\\' + dirs + '\\index.html', 'r+', encoding='utf-8') as htmlfile:
htmlstr = htmlfile.read()
newhtmlstr = htmlstr.replace('src="index.', 'src="' + path + '\\' + dirs + '\\' + 'index.')
newhtml = open(path + '\\' + dirs + '\\index1.html', 'w', encoding='utf-8')
newhtml.write(newhtmlstr)
newhtml.close()
pypandoc.convert_file(path + '\\' + dirs + '\\index1.html', 'docx',
outputfile=path + '\\' + dirs + '\\' + htmlname + '.docx')
i += 1
print('正在处理' + htmlname + '.docx', str(i) + '/' + str(zong),f"成功数量{str(i)},失败数量{str(j)}")
elif dirs.endswith("_DOC"):
htmlname = dirs.replace("_DOC", "")
with open(path + '\\' + dirs + '\\index.html', 'r+', encoding='utf-8') as htmlfile:
htmlstr = htmlfile.read()
newhtmlstr = htmlstr.replace('src="index.', 'src="' + path + '\\' + dirs + '\\' + 'index.')
newhtml = open(path + '\\' + dirs + '\\index1.html', 'w', encoding='utf-8')
newhtml.write(newhtmlstr)
newhtml.close()
pypandoc.convert_file(path + '\\' + dirs + '\\index1.html', 'docx',
outputfile=path + '\\' + dirs + '\\' + htmlname + '.docx')
i += 1
print('正在处理' + htmlname + '.docx', str(i) + '/' + str(zong),f"成功数量{str(i)},失败数量{str(j)}")
except Exception:
print(f'有异常,成功数量{str(i)},失败数量{str(j)}')
j+=1
continue
print(f"执行结束,")解释:
1、首先导入os包,这个包是操作文件的包。
2、导入pypandoc包,使用这个包将来生成word文档。
3、需要安装pandoc软件,如果之前没有安装过这个软件,在使用pypandoc会提示下载地址的。
4、使用os包来读取目标路径下有多少html文件。
5、使用for循环来遍历这些文件,并读取他们
6、使用pypandoc包将读取到的数据生成word文档。
使用五六十行python代码,在短短几十秒的时间就能完成人工需要十天半个月的工程,是不是很实用呢?
上一篇:使用pyqt构建桌面图形应用
下一篇:使用python生成动态条形图